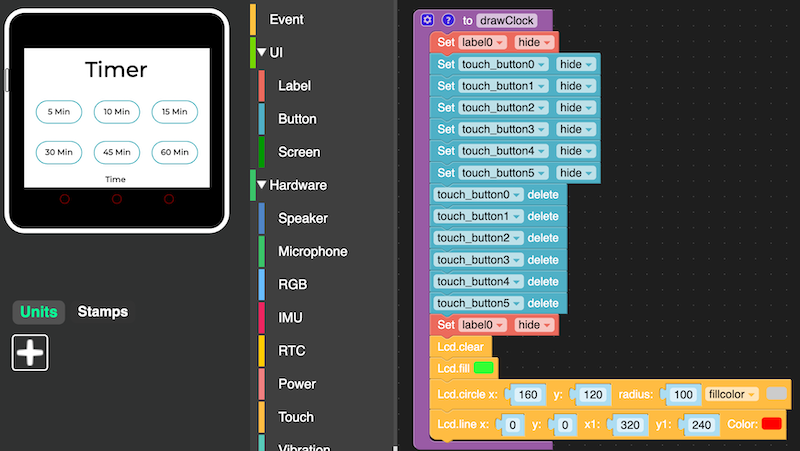
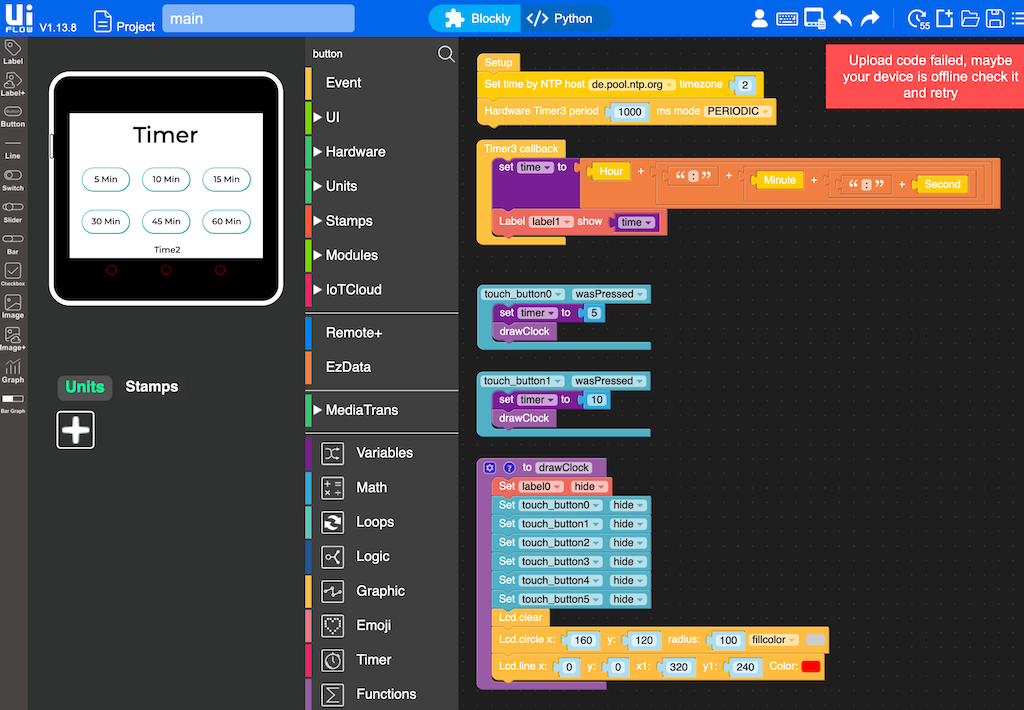
Well, and there is always the option to just strip it down to the basics.
# urlencode.py
_ALWAYS_SAFE = frozenset(b'ABCDEFGHIJKLMNOPQRSTUVWXYZ'
b'abcdefghijklmnopqrstuvwxyz'
b'0123456789'
b'_.-')
_ALWAYS_SAFE_BYTES = bytes(_ALWAYS_SAFE)
def quote(string, safe='/', encoding=None, errors=None):
"""quote('abc def') -> 'abc%20def'
Each part of a URL, e.g. the path info, the query, etc., has a
different set of reserved characters that must be quoted.
RFC 2396 Uniform Resource Identifiers (URI): Generic Syntax lists
the following reserved characters.
reserved = ";" | "/" | "?" | ":" | "@" | "&" | "=" | "+" |
"$" | ","
Each of these characters is reserved in some component of a URL,
but not necessarily in all of them.
By default, the quote function is intended for quoting the path
section of a URL. Thus, it will not encode '/'. This character
is reserved, but in typical usage the quote function is being
called on a path where the existing slash characters are used as
reserved characters.
string and safe may be either str or bytes objects. encoding must
not be specified if string is a str.
The optional encoding and errors parameters specify how to deal with
non-ASCII characters, as accepted by the str.encode method.
By default, encoding='utf-8' (characters are encoded with UTF-8), and
errors='strict' (unsupported characters raise a UnicodeEncodeError).
"""
if isinstance(string, str):
if not string:
return string
if encoding is None:
encoding = 'utf-8'
if errors is None:
errors = 'strict'
string = string.encode(encoding, errors)
else:
if encoding is not None:
raise TypeError("quote() doesn't support 'encoding' for bytes")
if errors is not None:
raise TypeError("quote() doesn't support 'errors' for bytes")
return quote_from_bytes(string, safe)
def quote_plus(string, safe='', encoding=None, errors=None):
"""Like quote(), but also replace ' ' with '+', as required for quoting
HTML form values. Plus signs in the original string are escaped unless
they are included in safe. It also does not have safe default to '/'.
"""
# Check if ' ' in string, where string may either be a str or bytes. If
# there are no spaces, the regular quote will produce the right answer.
if ((isinstance(string, str) and ' ' not in string) or
(isinstance(string, bytes) and b' ' not in string)):
return quote(string, safe, encoding, errors)
if isinstance(safe, str):
space = ' '
else:
space = b' '
string = quote(string, safe + space, encoding, errors)
return string.replace(' ', '+')
def quote_from_bytes(bs, safe='/'):
"""Like quote(), but accepts a bytes object rather than a str, and does
not perform string-to-bytes encoding. It always returns an ASCII string.
quote_from_bytes(b'abc def\x3f') -> 'abc%20def%3f'
"""
if not isinstance(bs, (bytes, bytearray)):
raise TypeError("quote_from_bytes() expected bytes")
if not bs:
return ''
if isinstance(safe, str):
# Normalize 'safe' by converting to bytes and removing non-ASCII chars
safe = safe.encode('ascii', 'ignore')
else:
safe = bytes([c for c in safe if c < 128])
if not bs.rstrip(_ALWAYS_SAFE_BYTES + safe):
return bs.decode()
try:
quoter = _safe_quoters[safe]
except KeyError:
_safe_quoters[safe] = quoter = Quoter(safe).__getitem__
return ''.join([quoter(char) for char in bs])
def urlencode(query, doseq=False, safe='', encoding=None, errors=None):
"""Encode a dict or sequence of two-element tuples into a URL query string.
If any values in the query arg are sequences and doseq is true, each
sequence element is converted to a separate parameter.
If the query arg is a sequence of two-element tuples, the order of the
parameters in the output will match the order of parameters in the
input.
The components of a query arg may each be either a string or a bytes type.
When a component is a string, the safe, encoding and error parameters are
sent to the quote_plus function for encoding.
"""
if hasattr(query, "items"):
query = query.items()
else:
# It's a bother at times that strings and string-like objects are
# sequences.
try:
# non-sequence items should not work with len()
# non-empty strings will fail this
if len(query) and not isinstance(query[0], tuple):
raise TypeError
# Zero-length sequences of all types will get here and succeed,
# but that's a minor nit. Since the original implementation
# allowed empty dicts that type of behavior probably should be
# preserved for consistency
except TypeError:
# ty, va, tb = sys.exc_info()
raise TypeError("not a valid non-string sequence "
"or mapping object")#.with_traceback(tb)
l = []
if not doseq:
for k, v in query:
if isinstance(k, bytes):
k = quote_plus(k, safe)
else:
k = quote_plus(str(k), safe, encoding, errors)
if isinstance(v, bytes):
v = quote_plus(v, safe)
else:
v = quote_plus(str(v), safe, encoding, errors)
l.append(k + '=' + v)
else:
for k, v in query:
if isinstance(k, bytes):
k = quote_plus(k, safe)
else:
k = quote_plus(str(k), safe, encoding, errors)
if isinstance(v, bytes):
v = quote_plus(v, safe)
l.append(k + '=' + v)
elif isinstance(v, str):
v = quote_plus(v, safe, encoding, errors)
l.append(k + '=' + v)
else:
try:
# Is this a sufficient test for sequence-ness?
x = len(v)
except TypeError:
# not a sequence
v = quote_plus(str(v), safe, encoding, errors)
l.append(k + '=' + v)
else:
# loop over the sequence
for elt in v:
if isinstance(elt, bytes):
elt = quote_plus(elt, safe)
else:
elt = quote_plus(str(elt), safe, encoding, errors)
l.append(k + '=' + elt)
return '&'.join(l)
Then we can finally do a nicer GET with parameters:
import urequests
from urlencode import urlencode
url = 'http://server.tld/path/to'
params = {'key1': 'value1', 'key2': 'value2'}
if params:
url = url.rstrip('?') + '?' + urlencode(params, doseq=True)
print(url)
response = urequests.get(url)